استفاده از Rust برای کاربردهای عددی علمی: یادگیری از تجربیات گذشته
نویسنده فیلیپه از مرکز تحقیقاتی eScience هلند

من یک توسعهدهنده نرمافزار در مرکز eScience هلند هستم، جایی که ما با ارائه ابزارهای دیجیتالی مناسب برای تحقیقاتشان، همه محققان را در همه رشتههای علمی در هلند توانمند میسازیم. این را تصور کنید، یک دانشمند با ایده ای درخشان در مورد ایجاد یک ماده جدید برای بهبود سلول های خورشیدی یا یک الگوریتم انقلابی برای درک علم برهمکنش های پروتئینی، به سمت ما بیاید، اما او باید با نرم افزاری با کارایی بالا برای اجرای صدها شبیه سازی وارد میدان شود. بنابراین، ما با آنها همکاری می کنیم تا ابزارهای نرم افزاری را توسعه دهیم که می تواند ایده های آنها را به نتایج ملموس برساند.
برخی از این پروژه ها شامل شمار بسیاری محاسبات عددی هستند و بنابراین ما به ابزارهایی برای تولید برنامه های کاربردی سریع نیاز داریم: Rust یک زبان سطح پایین با جامعه ای استقبال کننده است که به دلیل عملکرد، سیستم مدیریت حافظه، سطح انتزاع بالا و اکوسیستم شکوفا، به عنوان یک رقیب قوی برای زبان های سنتی مانند C/C++/Fortran برای کاربردهای عددی است. کتاب Rust را بررسی کنید تا کلیتی از این زبان دستتان بیاید!
چیزی که من در مورد Rust دوست دارم این است که برای حل مشکلات عینی ساخته شده است و بر روی درس هایی (به طرز دردناکی) آموخته شده در هنگام پیاده سازی سیستم های واقعی ساخته شده است.
در مرکز علوم الکترونیک هلند، تمرکز اصلی من روی شیمی محاسباتی و علم مواد است. در این زمینه ها، از اصول مکانیک کوانتومی برای تولید مدل هایی استفاده می شود که امکان محاسبه خواص فیزیکی و شیمیایی جالب را فراهم می کند. این محاسبات به تعداد زیادی جبر خطی خلاصه می شود. در صورتی که این یک مفهوم ریاضی محض به نظر می رسد، اجازه دهید به شما بگویم که جبر خطی بستر ریاضی است که تمام برنامه های کاربردی یادگیری ماشین مدرن بر آن بنا شده اند.
زیبایی جبر خطی این است که بسیاری از مسائل علمی و مهندسی را می توان با استفاده از عملیات عددی بر روی بردارها و ماتریس ها مدل سازی کرد. در میان ابزارهای قدرتمند در جعبه ابزار جبر خطی، الگوریتمهایی برای یافتن مقادیر ویژه و بردارهای ویژه یک ماتریس معین، سنگ بنای ایجاد راهحلهای کمّی برای سؤالات متنوعی هستند مانند: «یک مولکول چقدر انرژی جذب میکند؟» یا “چقدر نیرو می توان روی پل اعمال کرد؟” از زمان شروع فیزیک محاسباتی، جامعه علمی مجموعهای از کتابخانهها و ابزارها را برای حل آن مسائل عددی تولید کرده است که عمدتاً به زبان C/C++/Fortran نوشته شدهاند.
حال سؤال این است: Rust چگونه با رویکردهای سنتی برای ساخت برنامههای مبتنی بر محاسبات عددی مقایسه میشود؟ در این پست، من قصد ندارم معیارهایی را برای مقایسه عملکرد ارائه کنم (اگر کنجکاو هستید که Rust چگونه با C/C++ مقایسه می شود، این معیار را بررسی کنید). در عوض، من بر آنچه که مهمترین جنبه های توسعه نرم افزار علمی می دانم تمرکز خواهم کرد: سرعت توسعه و قابلیت نگهداری.
اشتباه نکنید، عملکرد یک اولویت است. با این حال، اگر ما یک مدل از آب و هوا بسازیم که پیشبینی کند قرار است ظرف چند هفته زیر آب باشیم (من در هلند زندگی میکنم)، مطمئن شویم که مدل به خوبی آزمایش شده است و احتمال بروز خطای تقسیمبندی را منتفی باشد. در نتیجه برنخوردن به یک خطای تقسیم بندی (پس از چند هفته شبیه سازی)، آن هم در آخرین لحظات محاسبات بهتر از عملیکرد است. بنابراین قصد دارم به سوالات زیر بپردازم:
چقدر تلاش برای ساخت و استقرار نرم افزار لازم است؟
چگونه وابستگی ها را مدیریت کنم؟
آیا میتوانیم حداقل محصول قابل دوام (MVP) را در یک زمان معقول ایجاد کنیم؟
چقدر تلاش برای آزمایش، مستندسازی و نگهداری کد لازم است؟
چگونه برنامه را موازی کنم؟
پیاده سازی حل کننده مقدار ویژه
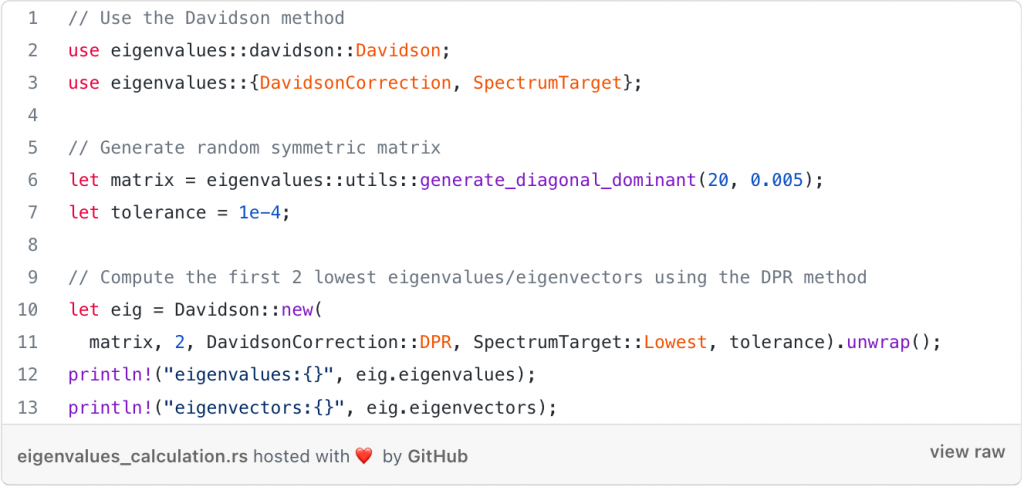
من با استفاده از تجربه ای که هنگام ایجاد یک بسته Rust (معروف به جعبه یا crates) به نام “مقدار ویژه” به دست آوردم، به سوالات بالا می پردازم که در آن چند الگوریتم را برای محاسبه مقادیر ویژه و بردارهای ویژه یک ماتریس معین پیاده سازی کرده ام.
در اینجا پیوند به کتابخانه مقادیر ویژه من است. همچنین می توانید نگاهی به مستندات داشته باشید.
قطعه کد زیر نحوه استفاده از کتابخانه مقادیر ویژه را نشان می دهد.
چقدر تلاش برای ساخت و استقرار نرم افزار لازم است؟

نرمافزارهای عددی معمولاً به کتابخانههای ریاضی بسیار بهینهشده (مانند OpenBlas، Lapack، Eigen و غیره) متکی هستند که عملیاتهای سطح پایین را ارائه میدهند که به عنوان بلوکهای ساختمانی برای توسعه محاسبات پیچیدهتر استفاده میشوند. این وابستگی ها معمولاً توسط مدیر سیستم یا با استفاده از یک مدیر بسته لینوکس (به عنوان مثال apt) نصب می شوند.
این وابستگی ها، همراه با سایر کتابخانه های متفرقه برای تجزیه، ثبت و غیره، با استفاده از چیزی مانند CMake به هم گره می خورند، که به زیبایی وابستگی های شما را کامپایل و پیوند می دهد. (:دی)
رویکرد قبلی روی کاغذ عالی کار می کند، اما در واقعیت، توسعه دهندگان زمان قابل توجهی را صرف یادگیری و نوشتن فایل های پیکربندی CMake می کنند (CMake ممکن است به خودی خود یک زبان برنامه نویسی نباشد اما در دسته یک گویش با ویژگی های خاص خود قرار می گیرد). علاوه بر این، جستجوی نسخه کامپایلر مناسب و نصب وابستگیهای صحیح بدون به هم ریختن کتابخانههای دیگر، کار را به قدری پیچیده میکند که افراد به معنای واقعی کلمه ترجیح میدهند به جای اینکه با جهنم وابستگی سروکار داشته باشند، مجموعه ابزارهای خود را نوشته و همیشه بروزرسانی کنند. بنابراین، شما در نهایت با نسخه مربوطه، CMake، وابستگیهای اصلی، کتابخانههای متفرقهای که خودتان پیادهسازی کردهاید، و (البته) کدتان، فروشندههای مختلف کامپایلر را فریب میدهید. شما نرم افزار را با همکاران خود به اشتراک می گذارید و آنها باید آن را در محیط خود نصب کنند و با جهنم وابستگی خود که احتمالاً با شما متفاوت خواهد بود مقابله کنند!
چگونه Rust (تا حدی) این آشفتگی را حل می کند؟
با CMake خداحافظی کنید! شما (یا سرپرست سیستم شما) هنوز باید کتابخانه های ریاضی بسیار بهینه شده اصلی را نصب کنید، اما مدیر بسته Rust (معروف به Cargo) همه وابستگی ها را برای شما حل، نصب و کامپایل می کند.
جامعه Rust بستههای بالغی را ارائه میکند که عملکرد مشترکی را که برای نوشتن برنامههای عددی نیاز دارید، ارائه میکند.
فایل وابستگی های من را بررسی کنید تا متوجه شوید که Cargo (مدیر بسته Rust) به چه نوع اطلاعاتی برای ساخت برنامه شما نیاز دارد. در این مورد، من از کتابخانه عالی nalgebra برای ساختن برخی الگوریتمها از API دستکاری آرایههای nalgebra استفاده میکنم.
آیا میتوانیم حداقل محصول قابل دوام (MVP) را در یک زمان معقول ایجاد کنیم؟
در کاربردهای علمی، ما اغلب با یک مدل یا فرضیه در ذهن شروع میکنیم و سپس نرمافزاری برای اثبات آن (یا رد آن) و اتصال نظریه به آزمایش میسازیم. با توجه به سطوح بالای عدم قطعیت، نمیتوانیم مطمئن باشیم که آنچه در حال توسعه هستیم به نتیجه خواهد رسید، قبل از سرمایهگذاری منابع انسانی ارزشمند در یک پروژه، باید یک نمونه اولیه یا حداقل محصول قابل دوام را بررسی کنیم تا صحت ایدههایمان را تأیید کنیم.
بنابراین، نوشتن یک MVP به زبانی مانند پایتون که امکان پیادهسازی سریع یک الگوریتم یا متد را با هزینه زمان اجرا (run-time) میدهد، معمول است (پایتون به طرز دردناکی کند است، اما برای نمونهسازی عالی است!). با توجه به پیچیدگی و سطح انتزاع پایین آن زبان ها، توسعه یک MVP در C یا Fortran بسیار خطرناک است، به این معنی که برای پیاده سازی مفاهیم مشابه، باید خطوط کد بیشتری را در مقایسه با پایتون بنویسیم.
اما اگر بتوانیم چیزی را تقریباً به سرعت پایتون اما با سرعت ++C پیاده سازی کنیم، چه؟ زنگ دوباره برای نجات!
هر برنامه نویس با تجربه ای می داند که بهره وری محصولش، به سطح انتزاعی زبان بستگی دارد. هر چه خطوط کد کمتری بنویسید، امکان ایجاد باگ های کمتری وجود دارد. با این حال، افزایش انتزاع اغلب منجر به هزینه بیشتر زمان اجرا می شود (کدی که باید بسیار سریع اجرا شود اغلب بسیار زشت است). Rust zero-cost abstraction به شما امکان می دهد با استفاده از انتزاع سطح بالاتر بدون هزینه محاسبات اضافی در زمان اجرا، کد مختصرتری بنویسید. تکرار کننده های Rust یک نمونه عالی از قدرت انتزاع هزینه صفر Rust هستند. قابل ذکر است که انتزاع هزینه صفر نیز در C++ مرکزی است.
چقدر تلاش برای نگهداری و بروزرسانی کد مورد نیاز است؟
اگر تا به حال در یک پروژه کدنویسی C/Fortran با اندازه متوسط تا بزرگ کار کرده باشید، مطمئنن می دانید که حفظ آن چقدر می تواند دشوار و خسته کننده باشد. یک شکایت مکرر در میان برنامه نویسان در این زبان ها، اشکالات وحشتناک مربوط به مدیریت ناامن حافظه است که ردیابی و بازتولید آن ممکن است روزها طول بکشد. برنامه نویسان فرترن به داشتن خطاهای تقسیم بندی برای صبحانه معروف هستند.
سیستم Rust به دلیل قابلیت هایش برای رد خطاهای حافظه در زمان اجرا متمایز است. جستجوگر قرض Rust ویژگی کشنده ای است که به از بین بردن تمام آن اشکالات حافظه کمک می کند و در عین حال سرعت بسیار بالایی را ارائه می دهد.
همچنین، همانطور که قبلا ذکر شد، انتزاع هزینه صفر Rust به شما این امکان را می دهد که یک پایه کد ناب را حفظ کنید که نگهداری آن آسان تر است.
نکته برای توسعه دهنده C++: اشاره گرهای هوشمند تا حدودی مشکلات مدیریت حافظه را کاهش می دهند، اما بررسی کننده قرض می تواند به شما کمک کند تا تضمین های ایمنی را به کدهای چندنخی گسترش دهید.
چقدر تلاش برای تست کد و نوشتن مستندات لازم است؟
نوشتن مستندات در C/C++/Fortran شامل استفاده از یک ابزار شخص ثالث مانند Doxygen است که باید آن را نصب و به باغ وحش CMake خود اضافه کنیم. همچنین، ما باید دستور زبان خاص این ابزار را برای نوشتن اسناد یاد بگیریم و سپس دعا کنیم که مستندات ساخته شوند.
مستندات نرم افزاری به دلیل ماهیت فرار تحقیقات علمی برای کد علمی ضروری است. نرم افزارهای علمی بدون مستندات، کدهای قدیمی نیستند، بلکه کدهای مرده هستند. با توجه به موانع بالای تحمیل شده توسط زبان های سنتی برای نوشتن اسناد، انتظار می رود که اکثر نرم افزارهای علمی به دلیل عدم امکان درک آنچه انجام شده است، حتی توسط متخصصان در همان زمینه (یا حتی گاهی اوقات توسط شخصی که آن را نوشته است، مرده به دنیا می آیند) .
مستندسازی پروژه Rust فقط مستلزم آن است که مستندات را با علامت گذاری در داخل کد منبع همانطور که در این مثال نشان داده شده است بنویسید. سپس شما فقط باید دستور cargo doc را اجرا کنید و تمام!
آزمایش در C/C++/Fortran سرنوشت مشابهی دارد، آنها به فریمورک های شخص ثالث نیاز دارند که باید نصب و به CMake اضافه شوند. فرترن به دلیل فقدان یک چارچوب تست استاندارد برای آزمایش بسیار دردناک است و برنامه نویسان را مجبور می کند تا مجموعه ای از اسکریپت ها را برای فراخوانی باینری ها، تجزیه خروجی و بررسی نتایج حفظ کنند.
Rust یک سیستم داخلی برای آزمایش کد شما دارد، بدون کتابخانه شخص ثالث. شما می توانید تست های واحد برای بررسی عملکرد یکبارهی یک ماژول معین و همچنین تست های یکپارچه سازی برای بررسی رابط عمومی کد خود داشته باشید. حتی می توانید نمونه های موجود در مستندات را اجرا و تست کنید! به طور خلاصه، نوشتن و اجرای تست ها را بی دردسر انجام دهید.
کاهش مانع برای نوشتن تستها و مستندات یکی از ویژگیهای دست کم گرفته شدهی Rust است. شرط می بندم که همه ما موافقیم که کد بدون آزمایش و مستندات بی فایده است.
چگونه برنامه را موازی کنم؟

سلب مسئولیت: به دلیل ناآگاهی من از آخرین پیشرفتهای Rust در محاسبات چند گره (MPI) و یکپارچهسازی GPU، این دو موضوع را آشکارا نادیده میگیرم.
شبیهسازیهای علمی مانند پیشبینی آب و هوا، اتصال پروتئین، دینامیک سیالات و غیره از نظر محاسباتی سنگین هستند اما اغلب قابل موازیسازی هستند (حداقل روی کاغذ!). ناگفته نماند که ما می خواهیم از تمام هسته های موجود در یک دستگاه خاص استفاده کنیم. رویکرد استاندارد استفاده از چیزی مانند OpenMP است که شامل کتابخانههای زمان اجرا، دستورالعملهای کامپایلر و غیره برای پشتیبانی از برنامهنویسی چند نخی با حافظه مشترک است.
یک لحظه کاملاً ترسناک برای توسعه دهندگان نرم افزار علمی زمانی است که اجرای سریال در حال کار است و باید نسخه موازی جدیدی پیاده سازی شود. به طور جدی، پیادهسازی موازی در C/C+/Fortran به این معنی است که همه ناشناختههای ناشناخته شما در مورد مدیریت حافظه ناامن، ناگهان همه باگهای مشمئزکنندهای را که تاکنون از آنها نمیدانستید، آشکار میکنند و باید ساعتهای بیپایانی را برای ردیابی آن صرف کنید.
Rust به عنوان درمانی برای تمام آن ناامیدی و اتلاف وقت، رویکرد جدیدی را ارائه می دهد که به عنوان همزمانی بی باک ابداع شده است. این مفهوم به امکان نوشتن برنامه های موازی اشاره دارد که عاری از باگ های ظریف هستند و می توان آنها را بدون معرفی باگ های جدید رفع کرد.
اما Rust چگونه به این فرمول شگفت انگیز دست می یابد؟ به نظر می رسد که سیستم نوع Rust و سیستم مالکیت، آنچه را که صورت ایمن بین نخها به اشتراک گذاشته میشود، پیگیری میکند و از کامپایل تراکنشهای حافظه همزمان غیرقانونی که منجر به مشکلات زمان اجرا می شود، خودداری میکند. بنابراین، کامپایلر Rust هر زمان که بخواهید از حافظه به روشی ناامن استفاده کنید، با خوشحالی خطاهای کامپایل را افزایش میدهد، به جای اینکه گودزیلا را در میانه شبیه سازی خود آزاد کنید.

از آنجایی که Rust یک زبان برنامه نویسی سیستمی است، به جای انتخاب یک مدل موازی منفرد، چندین مدل سطح پایین مانند ارسال پیام، وضعیت اشتراک گذاری و غیره را امکان پذیر می کند. خبر خوب این است که ما نیازی به استفاده از ماژولهای اولیه نداریم. می توانیم از کتابخانه های ارائه شده توسط جامعه راست مانند Rayon که بر روی آن موارد اولیه ساخته میشوند استفاده کنیم.
Rayon عملکرد قدرتمندی مانند تکرار کننده های موازی را ارائه می دهد که به ما امکان می دهد عملیات روی عناصر یک تکرار کننده را به صورت موازی و با حداقل تغییرات در کد منبع اجرا کنیم.
حتی بهتر از آن، میتوانید از کتابخانههایی مانند ndarray که دارای API به سبک Numpy است برای دستکاری آرایهها استفاده کنید، در حالی که به طور همزمان ویژگیهایی مانند رابط را برای Rayon ارائه میدهد تا عملیات آرایههای خود را به صورت موازی اجرا کند.
چالش های استفاده از Rust برای کاربردهای علمی
Rust یک زبان امیدوارکننده برای کاربردهای علمی است، اما چالشهای متعددی وجود دارد که باید قبل از اینکه زبان مورد توجه جامعه علمی قرار گیرد، بر آنها غلبه کرد.
Rust یک زبان سطح پایین با بسیاری از ویژگی های قدرتمند است. به عبارت دیگر، در واقع شما Rust را در بعدازظهر شنبه هنگام نوشیدن موهیتو یاد نمی گیرید. قبل از اینکه بتوانید با اطمینان شروع به نوشتن کنید، به تلاش و زمان قابل توجهی نیاز است. خوشبختانه جامعه Rust بسیار باز و پذیرا است و همیشه افرادی وجود دارند که مایل به کمک هستند. علاوه بر این، کامپایلر دارای آموزنده ترین پیام های خطا است که من در هر زبان برنامه نویسی دیده ام. به طور خلاصه، منحنی یادگیری از پایتون تندتر است، اما شما یک زبان امن برای حافظه خواهید داشت که همه آنها را کنترل می کند.
ممکن است عملکردی وجود داشته باشد که هنوز وجود نداشته باشد یا ناپایدار باشد. اکوسیستم Rust به سرعت در حال رشد است و افراد بیشتری با کتابخانه های بزرگ بیرون می آیند. انجمن همیشه خوشحال است که به شما کمک کند تا راه حلی برای عملکرد از دست رفته خود بیابید.
قابلیت همکاری با C/C++. ما مطمئناً نمیخواهیم همه چیز را از ابتدا بازنویسی کنیم، بنابراین میخواهیم تا آنجا که میتوانیم از C/C++ از کد دوباره استفاده کنیم. برای جامعه Rust، قابلیت همکاری روان با C/C++ اولویت اصلی است.
نظر دیگری دارید؟
امیدوارم بتوانم در مورد استفاده از Rust برای برنامه های کاربردی نرم افزار علمی به شما ایده بدهم. نظرات و افکار قابل قدردانی است.
دیدگاه کاربران(0)
ارسال دیدگاه
نویسنده

admin
| 10 مقاله |
درباره مقاله
| 993 مشاهده |
| تاریخ انتشار : پنجشنبه, 10 شهریور 1 |
| 0 نظر |
| دسته بندی : دستهبندی نشده |
| برچسب : rust برنامه نویسی زبان برنامه نویسی راست مکانیک کوانتومی |
| لینک کوتاه : |
جدیدترین آموزش ها
جدیدترین مقالات
-
 فاز بری (فاز هندسی) به زبان ساده به همراه یک مثال از سامانه های دو ترازی یکشنبه, 28 خرداد 2
فاز بری (فاز هندسی) به زبان ساده به همراه یک مثال از سامانه های دو ترازی یکشنبه, 28 خرداد 2 -
 چرا زبان راست (Rust) برای محاسبات کوانتومی مناسب است؟ مدیریت حافظه – سادگی ساخت و استقرار برنامه – سطح انتزاع بالا و عملکرد سطح پایین (low level) – رقیبی جدی برای زبان های C/C++/Fortran پنجشنبه, 10 شهریور 1
چرا زبان راست (Rust) برای محاسبات کوانتومی مناسب است؟ مدیریت حافظه – سادگی ساخت و استقرار برنامه – سطح انتزاع بالا و عملکرد سطح پایین (low level) – رقیبی جدی برای زبان های C/C++/Fortran پنجشنبه, 10 شهریور 1 -
 آشنایی با میانجی گرافیکی OpenMX_interface به پارسی چهارشنبه, 03 دی 99
آشنایی با میانجی گرافیکی OpenMX_interface به پارسی چهارشنبه, 03 دی 99 -
 انتشار نسخهی اولیه کد SciTube سه شنبه, 26 فروردین 99
انتشار نسخهی اولیه کد SciTube سه شنبه, 26 فروردین 99 -
 نحوه وصل شدن به کلاسترهای محاسباتی چهارشنبه, 11 دی 98
نحوه وصل شدن به کلاسترهای محاسباتی چهارشنبه, 11 دی 98

 Telegram
Telegram Linkedin
Linkedin Pinterest
Pinterest Twitter
Twitter